
The Synthetic Edge
Practical wins with synthetic data—and a federated route to real-world data unlock. A friendly, technical guide for builders, PMs, researchers, and curious humans.


Synthetic data is having a moment—but not everywhere. A recent interview of Sam Altman and panel discussion featuring Haseeb Qureshi nudged me to look past the hype and ask a simple question: where does synthetic data actually help, and where does it hurt?
We’re awash in claims that synthetic data will replace the real thing. It won’t. But used well, it’s a superpower. This guide cuts through the noise: what synthetic data is, where it shines (alignment, augmentation), where it fails (causality, compliance), and how federated learning lets you learn from private, real-world data without moving it—while supercharging the synthetic data loop.
TL;DR
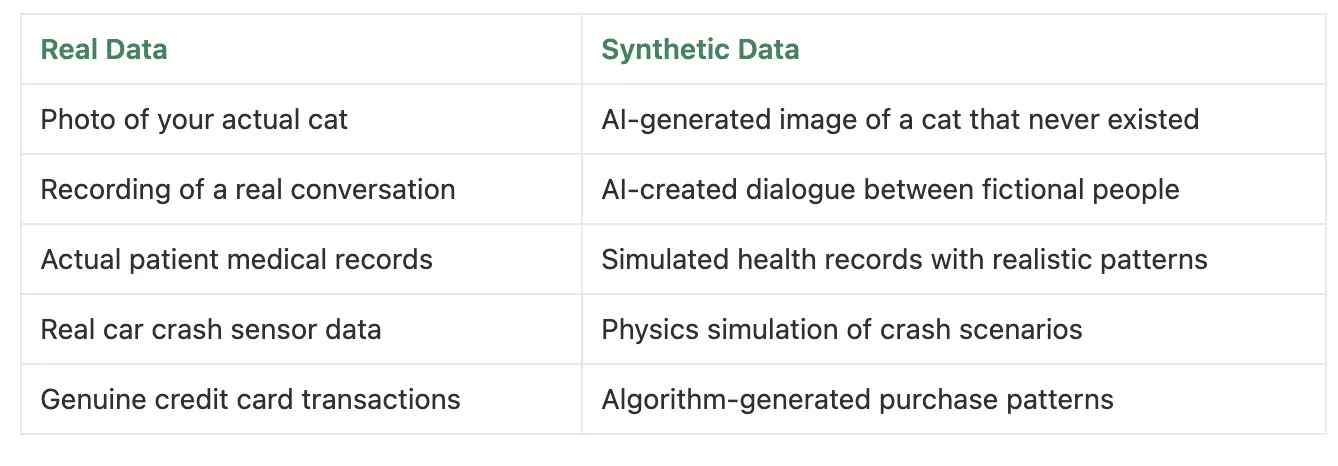
Synthetic data = data made by computers (models/simulators) to train other models.
Best fit: after base pretraining—alignment, instruction tuning, preference & safety data.
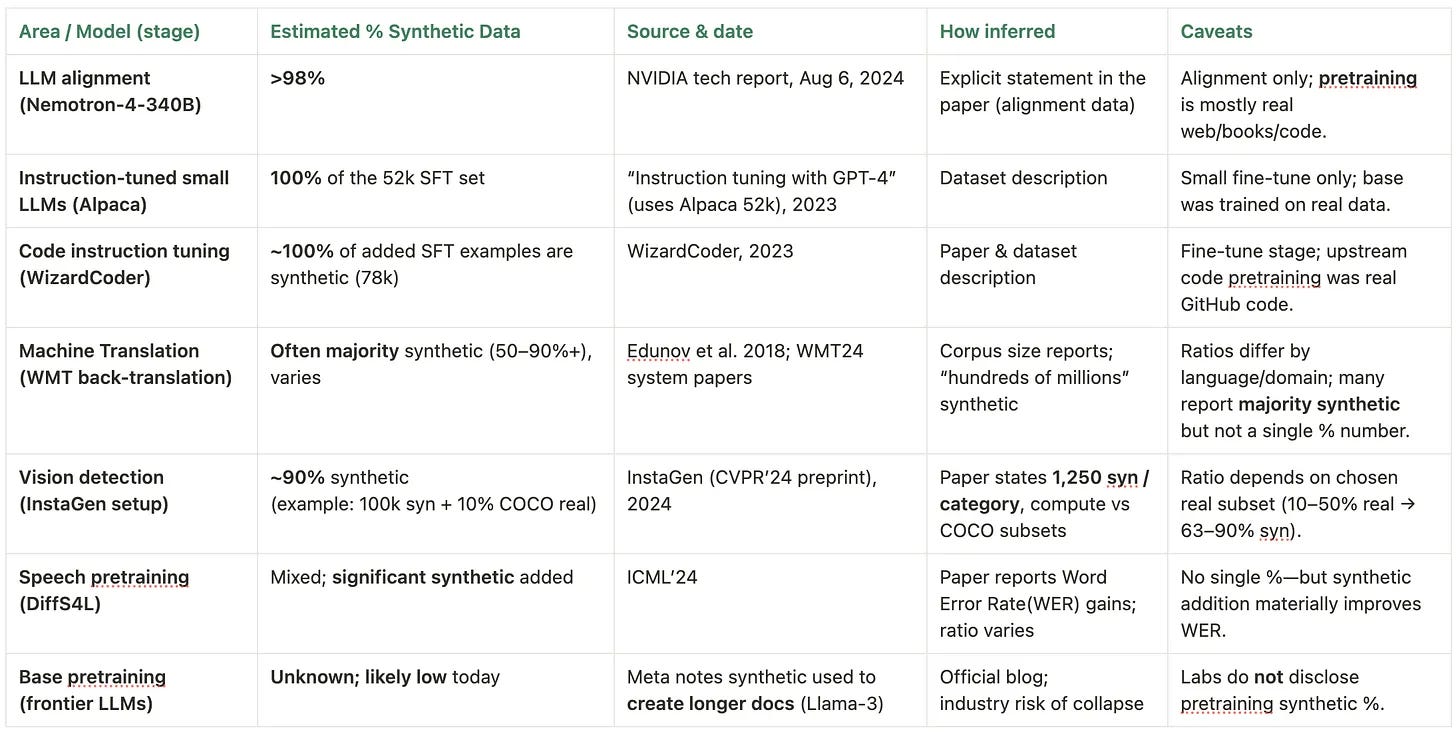
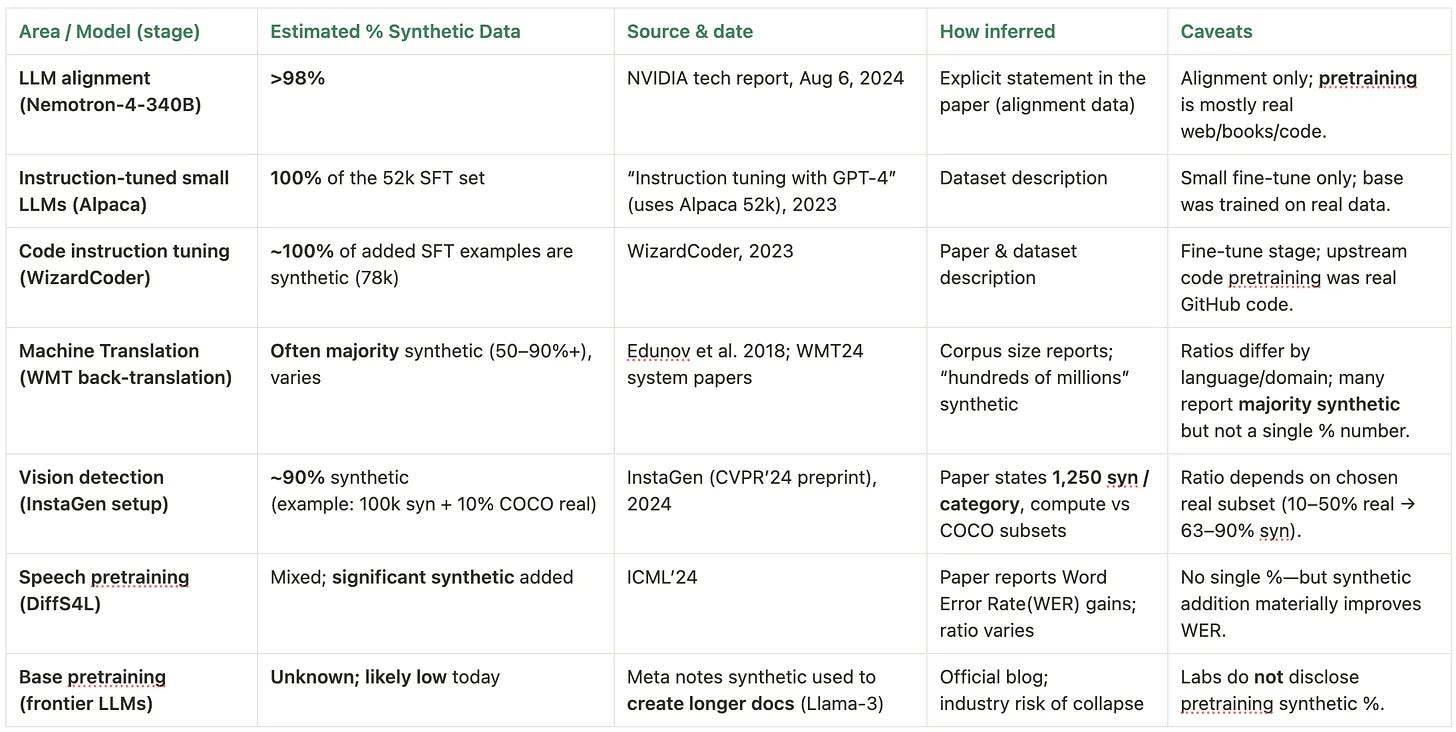
Today: post-training can be majority synthetic; base pretraining still leans heavily on human-authored web/books/code.
Post-training ≈ synthetic-heavy. Pre-training ≈ human-heavy
Trade-off: cheap and fast, but risks sameness & drift. Mix with real data and evaluate on fresh, human-curated sets.
Non-negotiable real data: domains needing outcomes/causality/compliance (healthcare, fraud, robotics failures, industrial logs).
Winning loop:
Generate → Judge/Filter → Mix with Real → Train → Evaluate → Repeat.
Why synthetic now?
The AI gold rush has hit a new bottleneck: not GPUs, but ground-truth data. Synthetic data offers a high-leverage fix—scaling datasets, filling critical gaps, preserving privacy, and enabling rapid iteration.
Its ROI is clearest in post-training: lower cost, faster cycles, and targeted improvements in model behavior. That’s why adoption of Synthetic Data is accelerating across leading AI companies, from consumer apps to autonomous systems.
What is synthetic data?
Data produced by models or simulators rather than collected from people/sensors.
Two analogies
Flight simulator: safely practice tricky scenarios.
Teacher’s practice set: real data = textbooks & life; synthetic = targeted exercises and mock exams.
Mini-glossary
Pretraining: large, general learning stage.
Post-training/alignment: teach behavior, safety, preferences.
Back-translation: make pseudo parallel data for MT.
Domain randomization: vary colors/lighting/layouts in simulations to boost robustness.
Big idea: It’s not real vs synthetic—it’s how you mix them.
Where synthetic dominates (and where it doesn’t)
Shines
Alignment & instruction tuning: large shares are synthetic (preference data, safety rules, self-instruct style data).
Machine translation: back-translation creates useful pairs from monolingual text.
Vision/robotics: simulators generate rare/unsafe scenes; domain randomization improves transfer.
Speech: synthetic augmentation can cut Words Error Rate(WER) in low-resource accents/noise conditions.
Still anchored in real
Base pretraining for frontier LLMs: heavy on human web/books/code; labs may use synthetic selectively (e.g., lengthening docs), but full mixes aren’t public.
Outcomes & causality: medical, fraud, industrial failures, robot accidents require ground-truth links over time that pure synthetic can’t invent.
Evaluation & compliance: hold-out, human-curated evals; provenance/consent trails for regulated sectors.
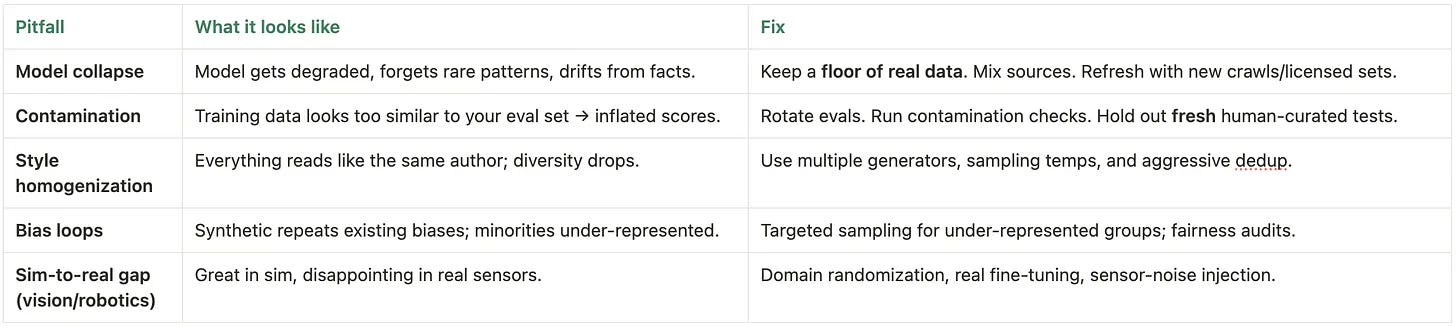
The dark side (and how to avoid it)
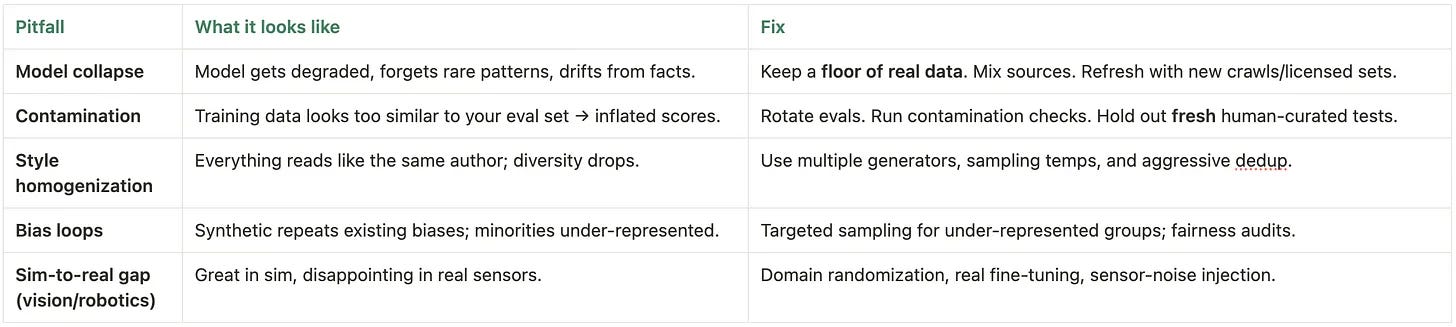
Model collapse. Re-training on your own synthetic outputs for multiple generations shrinks diversity and erodes factuality—like photocopying a photocopy until details vanish.
Contamination. If synthetic data overlaps with (or mimics) your eval set, scores look great while the model stays weak where it matters.
Style homogenization & bias loops. One generator’s voice and biases echo through the corpus, making everything sound the same and under-serving minority groups.
Sim-to-real gap. Policies that ace simulation stumble on real sensors, physics, and noise.
Fixes that work
Keep a floor of fresh real data; deduplicate aggressively. Maintain a minimum % of human-authored data in every batch and strip near-duplicates to avoid echo chambers.
Vary your generators and sampling. Mix models, prompts, seeds, and temperatures; rotate evals and run contamination checks (n-gram/embedding similarity) to keep tests clean.
Target the long tail. Upweight minority cohorts and edge cases (active learning/stratified sampling) so the model doesn’t regress to the mean.
For simulation: randomize, then fine-tune on real. Use domain randomization to widen coverage and finish with a short real-world fine-tune to close the sim-to-real gap.
How teams actually use synthetic data (today)
Augmentation (most common): +10–20% synthetic to cover rare/edge cases.
Ex: banks add synthetic scams to balance fraud datasets.
Replacement (sweet spot): swap costly human labels for synthetic preferences/critique.
Ex: large shares of alignment data are synthetic, cutting labeling cost/time.
Innovation (frontier): scenarios not capturable in the wild.
Ex: autonomous driving simulating long-tail traffic events.
Federated Learning + Synthetic amplification (emerging): combine privacy-preserving FL with synthetic generation to multiply learning without sharing raw data.
The federated learning bridge: unlocking private data for AI training
What FL does: trains models where the data lives (phones, hospitals, factories) and shares only model updates—not raw data.
How synthetic helps FL
Amplifies small local datasets (esp. rare demographics/cases).
Balances cohorts across sites; reduces privacy risk.
Bootstraps adaptation before on-device fine-tuning.

Flow
Local train: each site trains on its private data.
Generate: create synthetic reflecting local patterns (with strict privacy checks).
Share: send updates and optionally a curated synthetic slice.
Aggregate: global model benefits from diversity + volume.

At SoraChain AI, we’re building a trustless coordination layer for federated learning: a network where trainer nodes learn on private data and aggregator nodes combine updates with verifiable provenance. Synthetic data is a first-class citizen—used to amplify rare cohorts, stress-test safety, and pre-warm models before on-device FL.
Real-world case: Gboard (mobile keyboards)
On-device FL fine-tunes small LMs; privacy preserved.
Domain-adaptive synthetic text mimics typing styles/errors.
Reported result: ~22.8% relative lift in next-word prediction and faster convergence vs. using web text alone—without collecting raw keystrokes.
Conclusion
Synthetic is a force multiplier, not a substitute for reality.
Keep a minimum % real in every batch; de-dup and de-contaminate.
Evaluate on fresh, human sets.
Use FL when data can’t move; use synthetic to cover rare/long-tail.
Optimize cost per quality point, not dataset size.
If you follow this, your models get sharper, cheaper, safer—in that order.
If You’re Deep in Federated Learning, I’d Love Your Input
Have you spent time building, researching, or championing federated learning systems? Your insights could help sharpen the ideas at SoraChain AI. As I continue exploring federated learning, I’d love to hear from you.
If you’re an FL researcher, expert, advocate, or entrepreneur, please take a few minutes to share your perspective in this short survey → Link
References:
NVIDIA Nemotron-4 340B (Alignment & Synthetic Data Pipeline)
Technical Report — “Over 98% of data used in our model alignment process is synthetically generated.”
Developer Blog — Description of synthetic data generation pipeline (SDG): Nemotron-4-340B-Instruct, Reward model, filtering, 100K conversational synthetic examples.
Blog Post (Maginative) — Overview of Nemotron-4 340B and synthetic data alignment process.
NVIDIA NeMo Framework Docs — Pipeline customization details and synthetic data generation methods.
Google Gboard: Federated Learning + Synthetic Data
Google Research Blog — “Synthetic and federated: Privacy-preserving domain adaptation with LLMs for mobile applications.” Describes domain-adaptive synthetic generation, FL with DP, and ~22.8% relative improvement in next-word prediction.
Research Examples Combining Federated Learning & Synthetic Data
FDKT Framework (2024) — Federated domain-specific knowledge transfer using synthetic data with differential privacy.
CTCL Framework (2025) — Differentially private synthetic text generation with clustering for private-domain adaptation.